前言
新人训练营以树神的 node 分享作为压轴节目 👏👏
我来整篇笔记 📒 ~
定义
万事万物都需要一个定义。那么 nodejs 是什么呢?
nodejs 是 javascript 的一个运行环境。浏览器也是 js 运行环境,但是作为一个沙盒环境,它与本机环境隔离,而 node 则位于服务端。
让我们来想想,当一个语言用来做服务器端使用语言,那么它该做些什么呢?网络请求/处理、文件 IO(读写)、数据库查写,或其它。
众所周知,js 在浏览器是没有权限读取文件的,那么为 web 而生的 js ,该如何运行在服务器端呢?请看它的架构。
架构
架构图如下: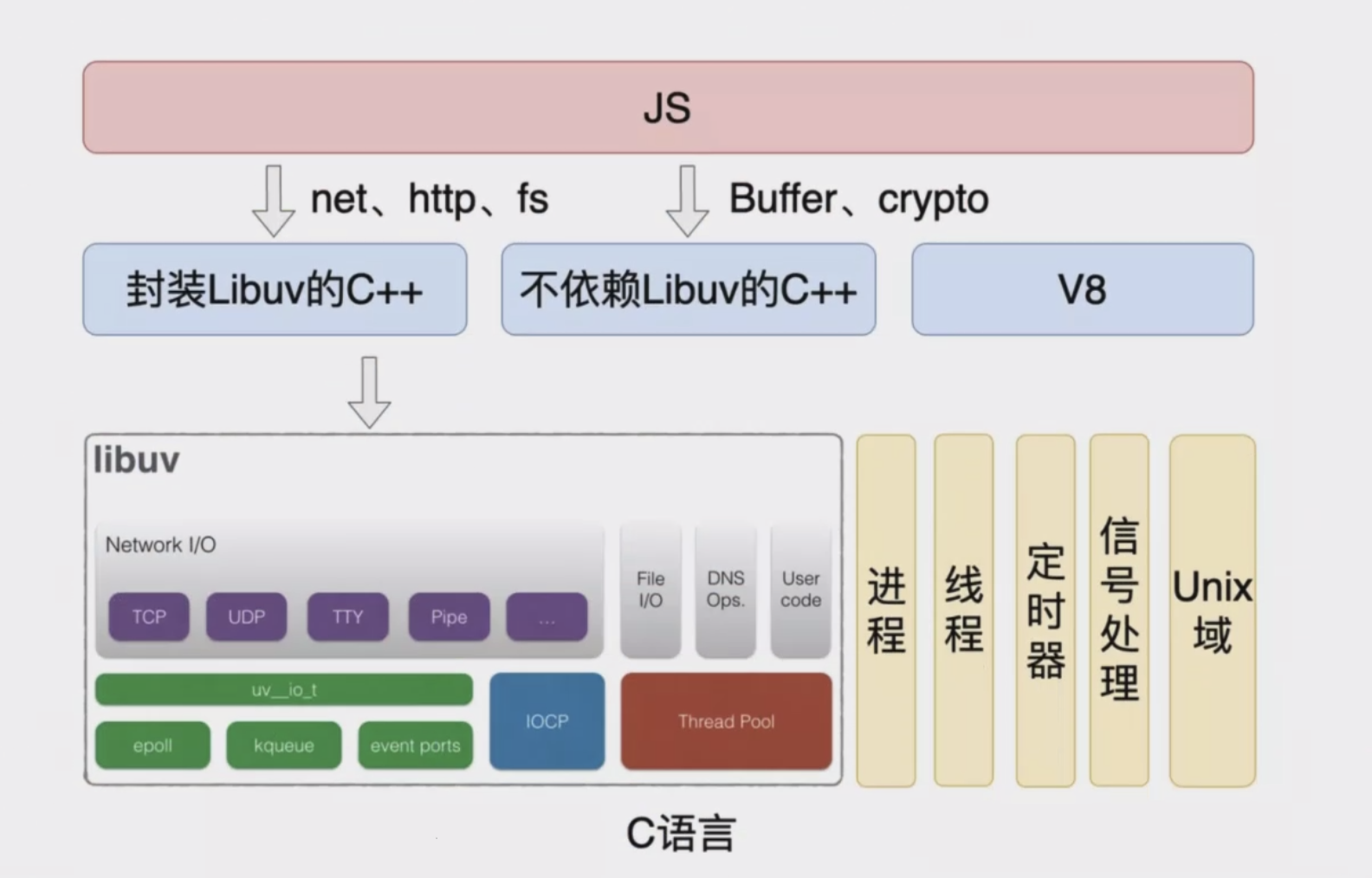
node 使用 chrome 的 V8 引擎来提供解释执行 JS 的能力,基于 C/C++ 来实现服务器端能力。
注意 V8 提供的仅是 JS 原生语法的解释执行,而与浏览器相关的功能,如 BOM 和 DOM,并不涉及。
对于服务器端能力,其中的网络、文件操作相关能力,由 libuv 提供。
libuv 是一个多平台 C 库,提供对基于事件循环的异步 I/O 的支持,有如下能力:
- 由 epoll、kqueue、IOCP、事件端口支持的全功能 事件循环
- 异步 TCP 和 UDP 套接字
- 异步 DNS 解析
- 异步文件和文件系统操作
- 文件系统事件
- ANSI 转义序列控制的 TTY
- IPC 经由套接字共享,使用 Unix 域套接字或命名管道(Windows)
- 子进程
- 线程池
- 线程和同步原语(primitive)
- 信号处理
- 高清晰度时钟
同时,还有一些其它的 C++ 模块,如 Buffer/Crypto,则不依赖 linuv,为 node 自行实现。
node 还允许开发者自定义 C++ 扩展。若有兴趣,可见(强如)死月写的《来一打 C++ 扩展》
启动流程
事件循环
示意图如下: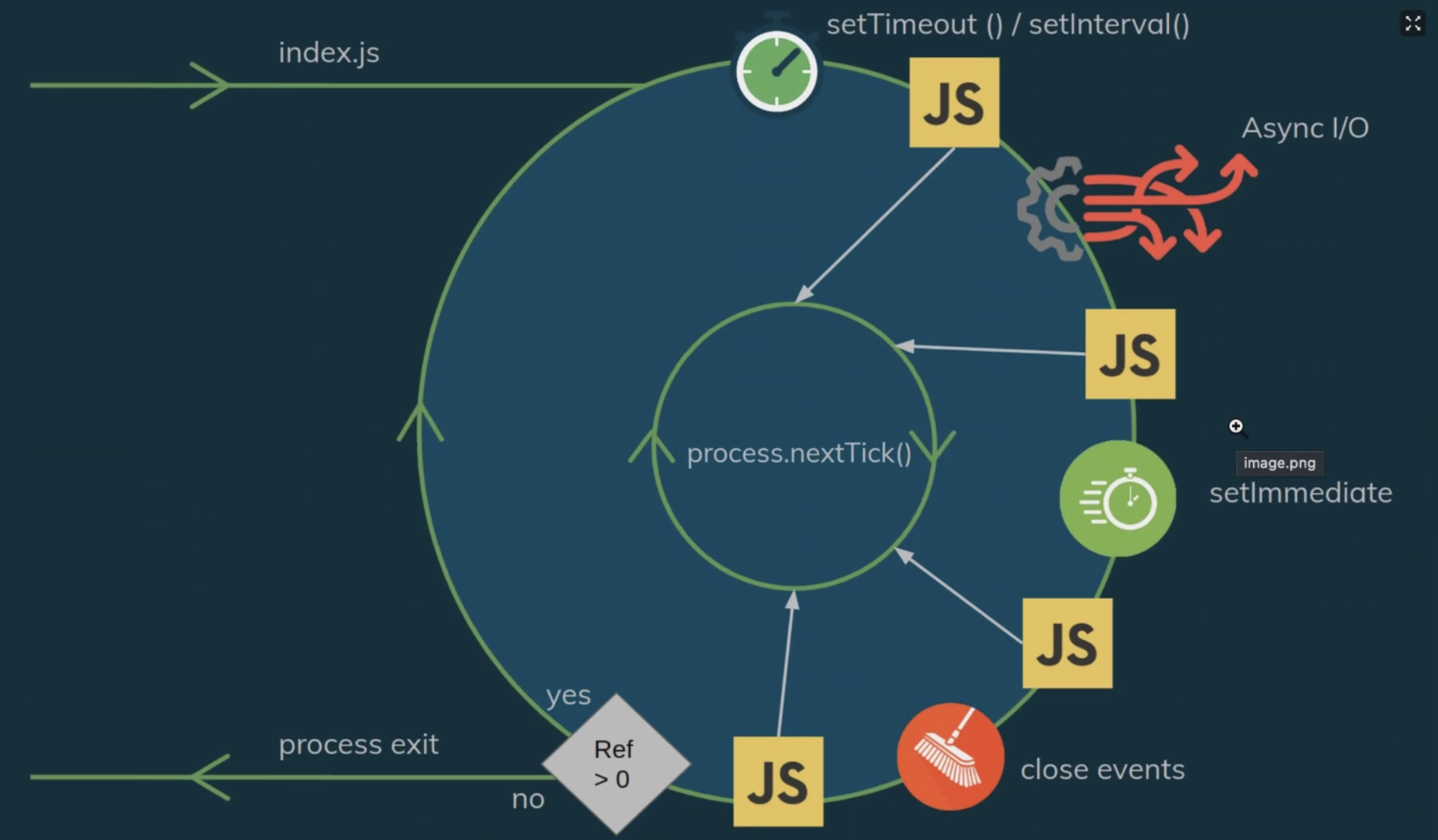
运行流程
Node 的运行流程如下:
- V8 引擎解析 JavaScript 脚本。
- 解析处理提供的脚本后,调用 Node API。
- libuv 库负责 Node API 的执行。它将不同的任务分配给不同的线程,形成一个 Event Loop(事件循环),以异步的方式将任务的执行结果返回给 V8 引擎。
- V8 引擎再将结果返回给用户。
所以说,事件循环是 Node 处理非阻塞 I/O 操作的机制,事件循环特性由 libuv 实现。
JS 是单线程处理的,但有时候,它们会把操作转移到系统内核中去。
目前大多数内核都是多线程的,它们可在后台处理多种操作。当其中的一个操作完成的时候,内核通知 Node 将适合的回调函数添加到 轮询 队列中等待时机执行。
例如文件 IO,主线程会直接把该任务给 libuv ,自己去执行其它任务,libuv 默认有 4 个线程,当 libuv 执行完该任务后,再把结果返回给主线程。
其中 libuv 引擎中的事件循环分为 6 个阶段,它们会按照顺序反复运行。
每当进入某一个阶段的时候,都会从对应的回调队列中取出函数去执行。当队列为空或者执行的回调函数数量到达系统设定的阈值,就会进入下一阶段。
6 个阶段
这里是 6 个阶段:
- timer 定时器:本阶段执行已经到点的 setTimeout() 和 setInterval() 的调度回调函数。
- 待定回调:处理一些上一轮循环中的少数未执行的 I/O 回调。
- idle, prepare:仅 node 内部使用。
- poll 轮询:
- 检索新的 I/O 事件;
- 执行与 I/O 相关的回调(几乎所有情况下,除了关闭的回调函数,那些由计时器和 setImmediate() 调度的之外),其余情况 node 将在适当的时候在此阻塞。
- check 检测:setImmediate() 回调函数在这里执行。
- 关闭的回调函数:一些关闭的回调函数,如:socket.on(‘close’, …)。
接下去详细介绍 timers、poll、check 这 3 个阶段,因为日常开发中的绝大部分异步任务都是在这 3 个阶段处理的。
timer
timers 阶段会执行 setTimeout 和 setInterval 回调,并且是由 poll 阶段控制的。
同样,在 Node 中定时器指定的时间也不是准确时间,只能是尽快执行。poll
poll 是一个至关重要的阶段,这一阶段中,系统会做两件事情:回到 timer 阶段执行回调,和执行 I/O 回调。
如果设定了 timer 的话且 poll 队列为空,则会判断是否有 timer 超时,如果有的话会回到 timer 阶段执行回调。
如果进入该阶段时没有设定 timer :若 poll 队列不为空,会遍历回调队列并同步执行,直到队列为空或者达到系统限制
若 poll 队列为空:
- 若有 setImmediate 回调需执行,进入 check 阶段
- 若无 setImmediate 回调需执行,会等待回调被加入到队列中并立即执行回调,这里同样会有个超时时间设置防止一直等待下去
check
setImmediate()的回调会被加入 check 队列中,check 阶段的执行顺序在 poll 阶段之后。
看一个例子:
console.log('start');
setTimeout(() => {
console.log('timer1');
Promise.resolve().then(function () {
console.log('promise1');
});
}, 0);
setTimeout(() => {
console.log('timer2');
Promise.resolve().then(function () {
console.log('promise2');
});
}, 0);
Promise.resolve().then(function () {
console.log('promise3');
});
console.log('end');输出结果是:
//start=>end=>promise3=>timer1=>timer2=>promise1=>promise2一开始执行栈的同步任务(这属于宏任务)执行完毕后(依次打印出 start end,并将 2 个 timer 依次放入 timer 队列),会先去执行微任务(这点跟浏览器端的一样),所以打印出 promise3
然后进入 timers 阶段,执行 timer1 的回调函数,打印 timer1,并将 promise.then 回调放入 microtask 队列,同样的步骤执行 timer2,打印 timer2;这点跟浏览器端相差比较大,timers 阶段有几个 setTimeout/setInterval 都会依次执行,并不像浏览器端,每执行一个宏任务后就去执行一个微任务。
process.nextTick
这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行。
setTimeout(() => {
console.log('timer1');
Promise.resolve().then(function () {
console.log('promise1');
});
}, 0);
process.nextTick(() => {
console.log('nextTick');
process.nextTick(() => {
console.log('nextTick');
process.nextTick(() => {
console.log('nextTick');
process.nextTick(() => {
console.log('nextTick');
});
});
});
});
// nextTick=>nextTick=>nextTick=>nextTick=>timer1=>promise1Node 与浏览器的 Event Loop 差异
浏览器环境下,microtask 的任务队列是每个 macrotask 执行完之后执行。而在 Node.js 中,microtask 会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行 microtask 队列的任务。
参考

- Post link: https://blog.mle.moe/2021/09/26/know-node/
- Copyright Notice: All articles in this blog are licensed under unless otherwise stated.
GitHub Issues